함수형 프로그래밍
함수형 프로그래밍은 프로그램의 주요 구성요소로 함수를 사용하며, 함수의 조합으로 프로그램을 작성하는 것을 강조합니다.
기본적으로 함수형 프로그래밍은 선언형 프로그래밍 의 특성을 함수들의 조합을 사용하여 구현하는 패러다임입니다.
그럼 선언형 프로그래밍은 뭘까요? 이를 위해서는 명령형 프로그래밍을 함께 이야기해야 합니다.
선언형 프로그래밍 vs 명령형 프로그래밍
선언형과 명령형의 차이는 무엇(What)을 할 것인지, 어떻게(How) 할 것인지를 설명하는 방식에 차이가 있습니다.
개발자는 먼저 명령형 프로그래밍을 기반으로 개발해 왔습니다. 다만 복잡하게 엉켜있는 코드를 관리하는 것은 매우 힘든 일이었습니다. 그렇기에 큰 문제를 작은 순수 함수로 나눠서 해결하는 기법인 함수형 프로그래밍 을 사용하기 시작했습니다.
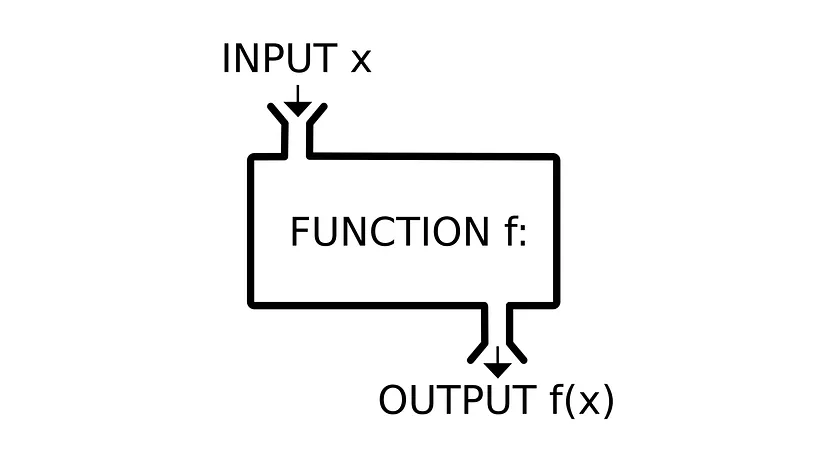
함수형 프로그래밍이라 불리는 이유는 프로그램이 입력을 인수로 받아 결과물을 생성하는 함수로 되어 있기 때문입니다.
함수형 프로그래밍의 특징
변수의 불변성 - "함수형 프로그래밍에는 대입문이 없다"
제목에 적혀있는 말은 클린 코드에서 Rober C.Martin이 한 말입니다. 대입문이 없다는 말은 함수형 프로그래밍에서 변수의 값을 변경하는 것이 아닌, 새로운 값을 계산하고 반환하는 방식을 강조합니다.
기존의 명령형 스타일을 보겠습니다.
var total = 0
for (i in 1..5) {
total += i
}
println(total) // 출력: 15명령형 프로그래밍에서는 대입문을 사용해 변수의 값을 변경하며, 프로그램의 상태(State)가 시간에 따라 변합니다. 이로 인해 코드의 예측 가능성과 디버깅이 어려워질 수 있습니다.
이제 함수형 스타일을 보겠습니다.
val total = (1..5).sum()
println(total) // 출력: 15함수형 프로그래밍에서는 `sum()` 함수를 사용해 원하는 결과를 얻으며, 변수의 값을 직접 변경하지 않습니다.
모듈화(Modularity)
함수형 프로그래밍은 다른 함수를 기반으로 정의되며, 이러한 함수들은 더 작은 함수들로 정의됩니다. 그렇기에 모듈화할 수 있다는 장점이 있습니다.

순수 함수(Pure Functions)
함수형 프로그래밍은 부수 효과가 없는 순수 함수를 1급 객체로 간주하여 파라미터나 반환값으로 사용할 수 있습니다.
순수 함수란 동일한 인자로 실행하면 항상 동일값을 반환하고, 부수 효과를 발생하지 않는 함수를 말합니다.
부수 효과(Side Effect)
부수 효과는 함수가 실행되는 과정에서 함수 외부의 데이터를 사용 및 수정하거나 외부의 다른 기능을 사용하는 것을 말합니다. 아래와 같은 경우가 부수 효과가 발생하는 경우입니다.
- 함수가 전역 변수를 사용하거나 값을 수정
- 함수가 키보드 입력를 받거나, 화면에 출력
- 파일 I/O 발생
- 예외나 오류가 발생하며 실행이 중단됨
- 함수에서 데이터베이스에 접근
1급 객체 함수(Pure Functions)
부수 효과가 없는 순수 함수를 1급 객체로 간주합니다. 1급 객체는 아래와 같은 특징이 있습니다.
- 변수에 할당할 수 있다.
- 매개변수의 인자로 전달할 수 있다.
- 반환 값으로 사용할 수 있다.
- 컬렉션 자료구조에 할당할 수 있다.
- 할당에 사용된 이름과 관계없이 고유한 구별이 가능하다.
- 동적으로 property 할당이 가능하다.
아래는 1급 객체 함수를 사용하는 예시입니다.
val add: (Int, Int) -> Int = { x, y -> x + y }
val subtract: (Int, Int) -> Int = { x, y -> x - y }
val result1 = add(10, 5)
val result2 = subtract(10, 5)
fun calculate(a: Int, b: Int, operation: (Int, Int) -> Int): Int {
return operation(a, b)
}
val result3 = calculate(10, 5, add)
val result4 = calculate(10, 5, subtract)
val map = mutableMapOf<String, (Int, Int) -> Int>()
fun main() {
println(result1) // 15
println(result2) // 5
println(result3) // 15
println(result4) // 5
map["더하기"] = add
map["곱하기"] = subtract
println(map)
}
지연 평가(Lazy Evaluation)
지연 평가는 어떤 연산이나 값을 필요할 때까지 계산을 미루는 방법입니다.
lazy 함수를 사용하거나 제너레이터 시퀀스 함수 부분함수 등을 사용해 지연 평가를 처리할 수 있습니다.
지연 평가는 계산이 필요한 시점에서 계산을 수행합니다. 가장 처음 값이 필요한 시점에서 계산을 수행하고 캐싱하여 동일한 값을 다시 계산하지 않도록 합니다. 아래의 코드를 보면 이해됩니다.
fun main() {
val lazyValue: Int by lazy {
println("지연 평가")
42
}
val result1 = lazyValue
val result2 = lazyValue
println("result1: $result1")
println("result2: $result2")
}
// 출력
// 지연 평가
// result1: 42
// result2: 42
무한 시퀀스를 만들면 실제 실행이 되지 않고 toList()가 실행되어야 무한 시퀀스가 실행됩니다.
fun main() {
val seq = generateSequence(0) { it + 100 }
println(seq.take(5).toList())
val out = outer(100)
println(out(200))
}
커링 함수(Currying)
커링 함수는 여러 개의 매개 변수를 받는 함수를 부분으로 나눠 처리하기 위한 방법입니다. 커링 함수를 사용하는 이유는 다양한 재사용과 마지막 매개변수가 입력될 때까지 함수의 실행 타이밍을 조절하기 위함입니다.
위에서 본 지연 평가가 커링 함수에서 이뤄집니다.
fun outer(x: Int): (Int) -> Int {
fun inner(y: Int): Int = x + y
return ::inner
}
커링 함수를 만드는 이유는 클로저 환경을 이용해서 상태를 보관하는 기능도 추가할 수 있기 때문입니다.
fun createAccumulator(initialValue: Int): (Int) -> Int {
var accumulator = initialValue
return { value ->
accumulator += value
accumulator
}
}
fun main() {
val adder = createAccumulator(0)
println("현재 합계: ${adder(5)}") // 5
println("현재 합계: ${adder(10)}") // 15
println("현재 합계: ${adder(-3)}") // 12
}
메서드 체인(Method Chain)
함수나 메서드가 연속으로 호출해서 처리하는 방식을 메서드 체이닝(chaining)이라고 합니다. 이전 함수의 반환값을 그대로 다음 함수에 전달하는 방식입니다.
예를 들어 짝수 배열을 만들고 싶다면 아래와 같이 할 수 있습니다.
(0..10).filter { it % 2 == 0 }.toIntArray() // [0, 2, 4, 6, 8, 10]
아래와 같이 확장 함수를 만들어서 체인을 구성할 수도 있습니다.
fun String.addPrefix(prefix: String): String {
return prefix + this
}
fun String.addSuffix(suffix: String): String {
return this + suffix
}
fun String.capitalizeWords(): String {
return this
.split(" ")
.joinToString(" ") {
it.capitalize()
}
}
fun main() {
val input = "hello world"
val result = input
.addPrefix("Prefix: ")
.addSuffix(" Suffix")
.capitalizeWords()
println(result) // Prefix: Hello World Suffix
}
다양한 함수
고차 함수(High-order Function)
고차 함수는 함수를 인자로 전달하거나 반환값으로 처리하는 함수를 말합니다.
fun calculate(a: Int, b: Int, operation: (Int, Int) -> Int): Int {
return operation(a, b)
}
fun main() {
val sum = calculate(10, 5) { a, b -> a + b }
val product = calculate(10, 5) { a, b -> a * b }
println("덧셈 결과: $sum") // 덧셈 결과: 15
println("곱셈 결과: $product") // 곱셈 결과: 50
}
고차 함수를 이용해서 두 개 이상의 함수가 결합된 함수를 합성 함수(Composition Function)라고 합니다.
fun combine(a: Int, b: Int, combinator: (Int, Int) -> Int, modifier: (Int) -> Int): Int {
val result = combinator(a, b)
return modifier(result)
}
fun main() {
val product = combine(10, 5, { a, b -> a * b }, { x -> x + 10 })
println("결합 결과: $product") // 결합 결과: 60
}
재귀 함수(Recursion Function)
재귀 함수란 함수 내에서 자기 자신을 호출하는 함수를 의미합니다. 팩토리얼을 계산할 때 보통 재귀 함수를 사용합니다.
fun factorial(n: Int): Long {
return if (n == 0 || n == 1) {
1
} else {
n.toLong() * factorial(n - 1)
}
}
fun main() {
val n = 5
val result = factorial(n)
println("$n! = $result") // 5! = 120
}다만 이런 일반적인 재귀 함수 코드에서 factorial 함수는 5번 호출되고 문맥을 유지하기 위해 factorial 함수가 가진 스택 메모리의 5배 만큼을 더 사용하게 됩니다.
이런 걱정을 해결해 메모리를 과도하게 사용하지 않도록 최적화하는 방법이 꼬리 재귀 처리를 하는 방법입니다.
tailrec fun factorial(n: Int, result: Long = 1): Long {
return if (n == 0 || n == 1) {
result
} else {
factorial(n - 1, n.toLong() * result)
}
}
fun main() {
val n = 5
val result = factorial(n)
println("$n! = $result") // 5! = 120
}꼬리 재귀 처리를 함으로써 반환값에서 추가 연산이 필요 없게 됩니다.
수신 객체 지정 람다
수신 객체는 확장 함수를 호출한 객체를 나타내는 말입니다.
수신 객체를 함수 자료형에 붙인 다음 람다 표현식을 받으면 수신 객체를 람다 표현식 내에서 사용할 수 있습니다. 이는 람다 표현식을 메서드처럼 사용할 수 있는 방안을 추가하는 것입니다.
우리가 자주 사용하는 스코프 함수가 바로 수신 객체 지정 람다로 되어있습니다.
아래는 확장 함수와 람다 표현식을 사용한 예시입니다.
val a : Int.(Int) -> String = {
"it: $it this: $this"
}예시는 Int형에 확장함수로 Int 매개변수를 받고 String을 반환하고 있습니다. 이때 함수 내부에서 리시버 객체인 this를 사용해 수신 객체를 가리킵니다.

반면 it은 람다 함수내에서 단일 매개변수를 가리킵니다. 위를 출력하면 이해가 잘 됩니다.
출력
it: 20 this: 10
수신 객체가 있는 경우에는 this를 써서 수신 객체에 접근할 수 있고, 매개변수가 있는 경우에는 it을 써서 매개변수에 접근할 수 있습니다.
수신 객체를 매개변수로 전달
수신 객체를 확장함수가 아니라 매개변수로 전달할 수도 있습니다.
스코프 함수
스코프 함수는 개체의 컨텍스트 내에서 코드 블록을 실행하는 것이 목적인 함수입니다. 스코프 함수의 종류로는 let, run, with, apply, also가 있습니다.
아래는 이를 나타낸 표입니다.

let
let은 제네릭 확장함수로 구성되었고 매개변수를 받아 함수의 실행 결과를 반환하는 함수입니다. Block 내에서 매개변수를 it으로 처리합니다.
inline fun <T, R> T.let(block: (T) -> R): R
let의 가장 큰 장점은 null이 될 수 있는 객체에 사용할 수 있다는 점입니다.
val str: String? = "Hello"
val length = str?.let {
println("let() called on $it")
it.length
}
run
run은 수신 객체가 있는 방식과 수신 객체가 없는 방식이 존재합니다. 따로 매개변수를 받지 않기 때문에 this를 사용해 수신 객체에 접근합니다.
inline fun <R> run(block: () -> R): R
inline fun <T, R> T.run(block: T.() -> R): R
수신 객체가 없는 run은 오직 람다 결과만을 반환합니다.수신 객체가 있는 run은 사실 let과 거의 같은 동작을 합니다.
fun main() {
val test = Test("name")
test.run{
println(name)
}
test.let{
println(it.name)
}
}
다만 아래와 같은 상황이라면 어떤 것을 사용해야 할지 조금 명확합니다. name이란 변수가 중복되기에 오해의 여지가 있을 수 있습니다.
fun main() {
val test = Test("name")
val name = "test"
test.run{
println(name)
}
test.let{
println(it.name)
}
}
let과 run은 block으로 넘어오는 람다의 매개변수가 있냐 없느냐로 나뉩니다.
inline fun <T, R> T.let(block: (T) -> R): R
inline fun <T, R> T.run(block: T.() -> R): R이런 차이로 인해 아래와 같이 it에 가독성을 높이기 위해 유의미한 이름을 줄 수 있습니다.
test.let { self ->
println(self.name)
}
with
with은 다른 리시버 함수와는 조금 다릅니다. 바로 수신 객체를 매개변수로 전달합니다.
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
...
return receiver.block()
}내부를 좀 더 자세하게 보면 결국 수신 객체에 람다 블록을 실행하고 있다는 점을 알 수 있습니다.
이러한 특성 때문에 run과 with은 매우 유사하지만 with은 chain call과 null 체크를 할 수 없습니다.
inline fun <T, R> T.run(block: T.() -> R): R
inline fun <T, R> with(receiver: T, block: T.() -> R): R
apply
apply는 리턴 타입이 없이 컨텍스트 객체 자체를 반환합니다. 그렇기에 반환 값을 갖지 않고 수신 객체의 멤버에 작용하는 코드 블록에 사용하는 것이 권장됩니다.
inline fun <T> T.apply(block: T.() -> Unit): T
also
also도 리턴 타입이 없이 컨텍스트 객체 자체를 반환합니다.
inline fun <T> T.also(block: (T) -> Unit): T
apply와 also는 let과 run과 같이 객체를 람다 파라미터로 받느냐, 수신 객체로 받는가에 차이가 있습니다.
class person {
var name = "kotlin"
private val id = "1541"
}
person.also {
println("my name is ${it.name}")
}
person.apply {
println("my name is $name")
}
이 둘의 차이는 apply와 also의 네이밍과 관련 있습니다.
apply는 객체를 수신 객체로 받기 때문에 객체에 접근할 때 this를 사용하며, 코드가 해당 객체의 외부가 아니라 객체 내부에 있는 듯한 인상을 줍니다.
반면 also는 객체를 람다 파라미터로 받기 때문에 객체에 접근할 때 it을 사용하며, 이는 코드가 객체 외부에서 해당 객체에 접근한다는 인상을 줍니다.
apply의 기능은 also로 구현할 수 있고, 반대도 마찬가지입니다. 다만 이러한 차이에 있어서 사용법이 달라질 수 있습니다.
SAM (Single Abstract Method) 인터페이스
하나의 추상 메서드만 가지고 있는 인터페이스를 함수형 인터페이스라고 하거나 SAM 인터페이스라고 합니다.
SAM 인터페이스는 여러개의 비 추상 메서드를 가질 수 있지만, 추상 멤버는 오직 하나만 가질 수 있습니다.
fun interface KRunnable {
fun invoke()
}
SAM 전환
SAM 전환을 통해 람다 표현식을 사용해서 코드를 더 간결하고 읽기 쉽게 만들 수 있습니다.
아래의 코드를 보겠습니다. 만약 SAM 전환을 사용하지 않는다면 아래와 같이 작성해야 합니다.
fun interface IntPredicate {
fun accept(i: Int): Boolean
}
val isEven = object : IntPredicate {
override fun accept(i: Int): Boolean {
return i % 2 == 0
}
}
SAM 전환을 활용하면 아래와 같이 간단하게 코드를 작성할 수 있습니다.
val isEven = IntPredicate { it % 2 == 0 }
인라인(Inline) 처리
가끔은 어떤 유형을 래퍼로 만드는 것이 필요할 때가 있습니다. 다만 이렇게 하면 추가적인 힙 할당으로 인해 런타임 오버헤드가 발생하거나 성능상의 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위해 Kotlin은 내부적으로 호출된 곳에 함수를 코드로 삽입해서 문제가 일어나는 것을 인라인 클래스라는 특별한 종류의 클래스를 도입했습니다. 인라인 함수는 이러한 특성을 가진 함수입니다.
인라인 함수
inline fun operateOnNumbers(a: Int, b: Int, operation: (Int, Int) -> Int): Int {
return operation(a, b)
}
fun main() {
val result = operateOnNumbers(5, 3) { x, y -> x + y }
println(result)
}
인라인 속성
noinline 처리
어떤 이유에서 인라인 함수 내에 매개변수로 전달되는 람다 표현식으로 코드 삽입을 금지할 수 있습니다.
inline fun operateOnNumbers(a: Int, b: Int, noinline operation: (Int, Int) -> Int): Int {
return operation(a, b)
}
crossinline 처리
람다가 자신을 감싼 함수 밖에서 반환되는 경우 (non-local return) crossinline 키워드를 사용하여 해당 람다가 인라인 함수 내에서 non-local return을 사용하지 못하도록 제한할 수 있습니다.
inline fun foo(f: () -> Unit) {
f()
}
fun main() {
foo {
println("Hello World")
return
}
}
아래의 예시를 보겠습니다. 아래의 인라인 함수에서는 람다 매개변수가 인라인이 아닌 다른 함수의 컨텍스트로 전달되고 있습니다.
inline fun foo(f: () -> Unit) {
bar { f() } // 오류발생!
}
fun bar(f: () -> Unit) {
f()
}
이러한 non-local return이 이뤄지는 경우에는 crossinline으로 처리하면 오류가 발생하지 않습니다.
inline fun foo(crossinline f: () -> Unit) {
bar { f() }
}
fun bar(f: () -> Unit) {
f()
}'스터디 > 코틀린 언어' 카테고리의 다른 글
| [Kotlin] 제네릭, 리플렉션, 애노테이션 - week 12 (0) | 2023.10.18 |
|---|---|
| [Kotlin] 위임 확장 - week 11 (0) | 2023.09.20 |
| [Kotlin] 추상 클래스, 인터페이스, Sealed 클래스 - week 9 (0) | 2023.09.07 |
| [Kotlin] 코틀린 컬렉션 - week 8 (0) | 2023.09.03 |
| [Kotlin] 클래스 추가 사항 - week 7 (0) | 2023.08.24 |
