머신러닝에 대해서는 아래의 유튜브를 통해 학습하였다.
데이터 세트 분리
데이터 세트 분리는 머신 러닝 모델을 학습, 검증 및 테스트하기 위해 사용되는 데이터를 적절하기 나누는 과정이다.
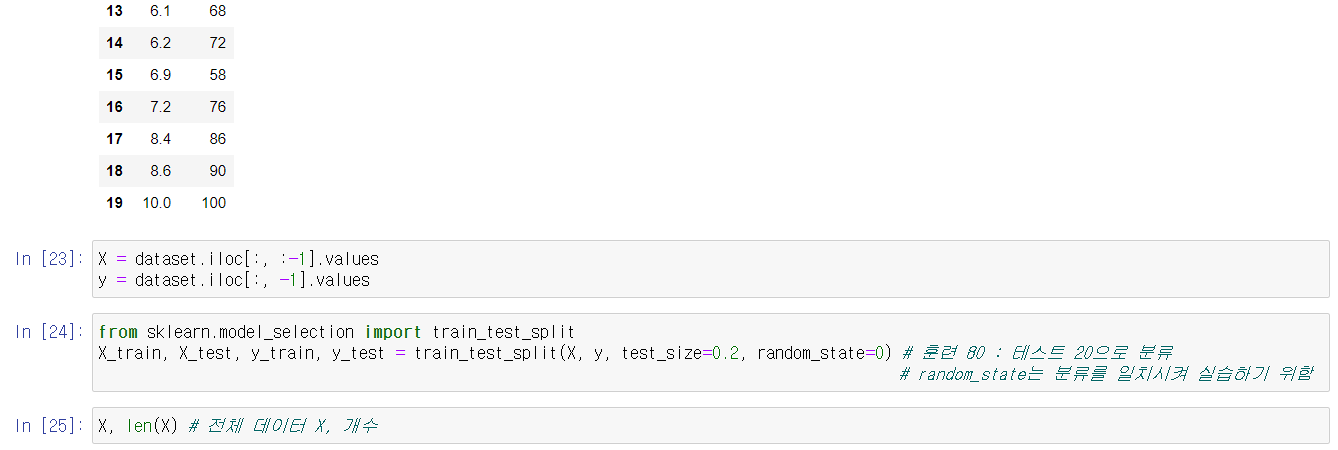
일반적으로 우리가 가지고 이는 데이터를 훈련 세트와, 테스트 세트로 분류를 하게 된다. 전체 데이터의 80에 해당하는 만큼을 가지고 머신 러닝 모델을 훈련시킨 다음, 나머지 20에 해당하는 테스트 세트로 모델이 잘 동작하는가 평가를 하게 된다.

데이터 세트 분리의 목적은 모델이 학습 데이터에 과적합 되지 않고 새로운 데이터에 대해 일반화할 수 있는 능력을 갖추도록 하는 것이다. 학습 세트를 사용하여 모델을 학습시키고 검증 세트를 사용하여 모델의 성능을 조정하며, 테스트 세트를 사용하여 최종적인 성능을 평가한다.
데이터 세트 분리는 일반적으로 무작위로 수행된다. 데이터 세트의 일정 비율을 각각의 세트에 할당하는 방식이 일반적이지만, 데이터의 특성과 사용하는 모델에 따라 다른 방법도 사용될 수 있다.
실습
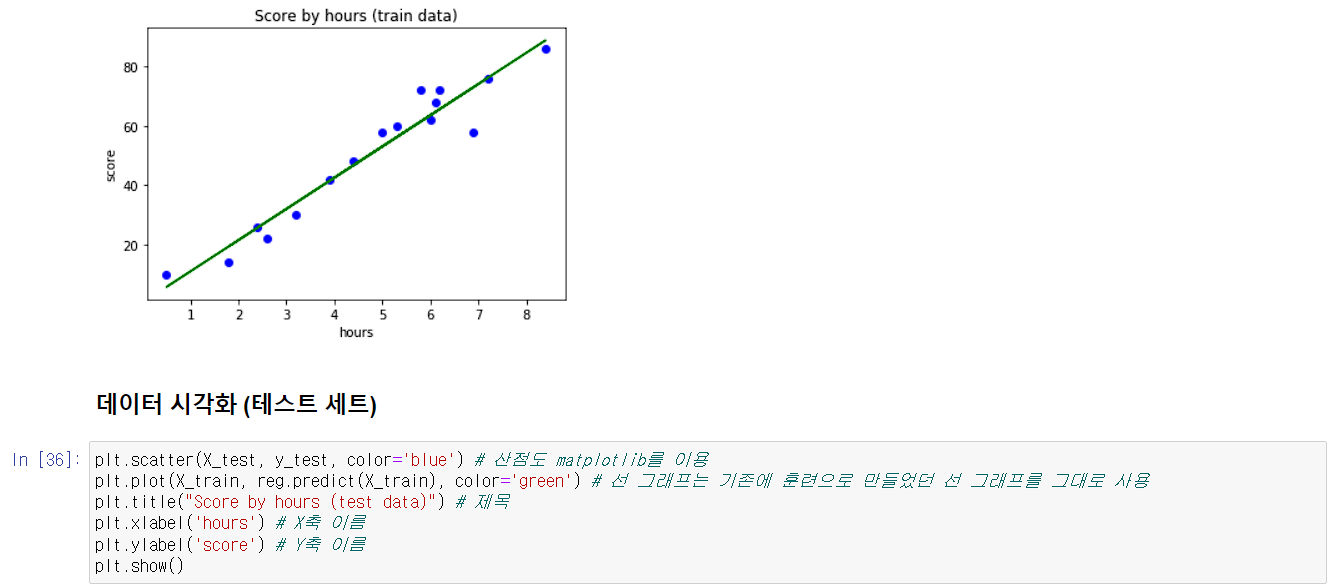
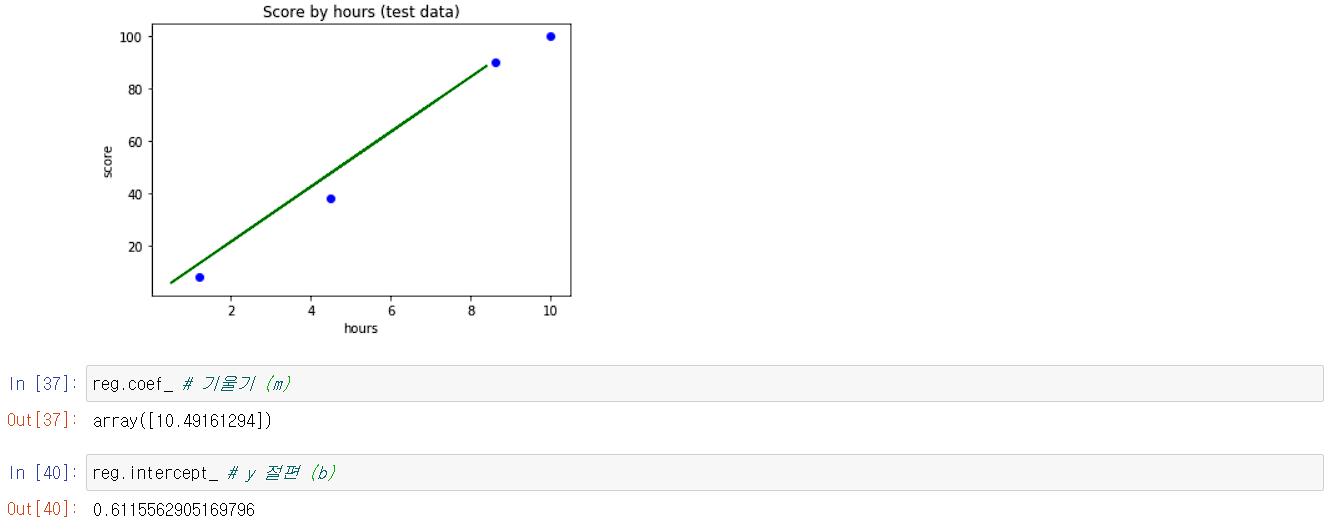
실습은 이전의 선형 회귀때 사용했던 데이터를 가지고 실습을 진행하겠다.





'인공지능 > Machine Learning' 카테고리의 다른 글
| 1-3. Gradient Descent (경사 하강법) (0) | 2023.05.09 |
|---|---|
| 1-1. Linear Regression (0) | 2023.05.09 |
| Machine Learning의 분류 (0) | 2023.05.08 |
